TOC
深度学习-第一个数字识别项目
今天按Google官方推荐流程,整理了开发模板,不是所有深度学习都严格按这个模板来实现,不同项目步骤有所删减,但大体框架是差不多的,主要为以下过程:
- 0.定义你的问题和目标。
- 1.构建你的数据集。
- 1.1.1 收集原始数据:大小、质量。
- 1.1.1.1.1质量-可靠性。遗漏的值、重复的例子、不良标签、不良特征。
- 1.2 识别特征和标签。
- 1.3 采样和分割数据集。
- 1.1.1 收集原始数据:大小、质量。
- 2.转换数据。
- 2.1 探索和清理数据
- 2.2 特征设计。
- 2.2.1 数值数据的转换
- 2.2.1 归一化:缩放、剪裁、对数缩放、Z-score
- 2.2.1 水桶化
- 3.训练一个模型。
- 4.部署一个模型。
## 0.定义你的问题和目标。
## 识别数字图片
# * 1.构建你的数据集。
# * 1.1.1 收集原始数据:大小、质量。
# * 1.1.1.1.1质量-可靠性。遗漏的值、重复的例子、不良标签、不良特征。
# * 1.2 识别特征和标签。
# * 1.3 采样和分割数据集。
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# * 2.转换数据。
# * 2.1 探索和清理数据
# * 2.2 特征设计。
# * 2.2.1 数值数据的转换
# * 2.2.1 归一化:缩放、剪裁、对数缩放、Z-score
# * 2.2.1 水桶化
x_train, x_test = x_train / 255.0, x_test / 255.0;
# * 3.训练一个模型。
import tensorflow as tf
print(tf.version)
## prepare loss_fn
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
## define sequesntial
model = tf.keras.Sequential();
## image input
model.add(tf.keras.layers.Flatten(input_shape=(28,28)))
## hidden layers
model.add(tf.keras.layers.Dense(128, activation='relu' ))
model.add(tf.keras.layers.Dropout(0.9))
## class output. Matching the numbers (0-9)
model.add(tf.keras.layers.Dense(10));
## 如果你想让你的模型返回一个概率,你可以将训练好的模型进行封装,并将softmax附加到它上
## model.add(tf.keras.layers.Softmax(10));
## model summary
model.summary()
## compile model
model.compile(optimizer='adam', loss=loss_fn, metrics=['accuracy']);
## fit model
model.fit(x_train, y_train, epochs=5)
## evaluate
model.evaluate(x_test, y_test, verbose=2)
## 4.deploy model
predictions = model.predict(x_test[:3])
print('predictions shape:', predictions)
## 4.deploy model
predictions = model.predict(x_test)
print('predictions shape:', predictions)
"""## using mabplot to show image"""
# import matplotlib.pyplot as plt
# plt.imshow(x_train[1])
解析:
- ReLU (Rectified Linear Unit)
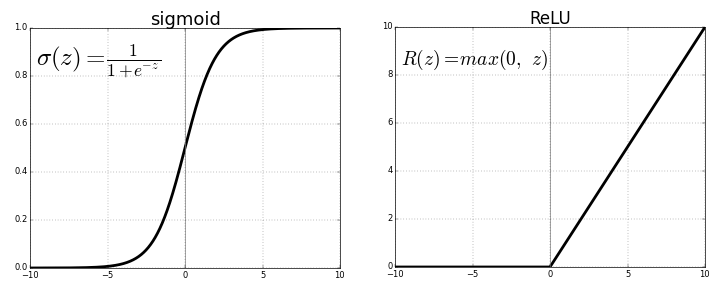
可以看出,ReLU是半整流(自下而上),当z小于零时,f(z)为零,当z大于或等于零时,f(z)等于z。
-
tf.keras.layers.Flatten意思是扁平化输入,将多维数组转换为一维数组。 -
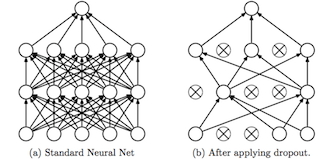
tf.keras.layers.Dropout如下图如示,Dropout是一种用于防止模型过度拟合的技术。Dropout的工作原理是在训练阶段的每次更新时,随机设置隐藏单元(构成隐藏层的神经元)的出边为0。
tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)分类交叉熵是一种损失函数,用于单标签分类。这是指每个数据点只适用于一个类别时。换句话说,一个例子只能属于一个类别。请注意。目标块之前的块必须使用激活函数Softmax。
Categorical_Crossentropy_math:
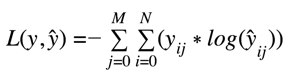
参考文献:
Activation Functions in Neural Networks
Dropout Neural Network Layer In Keras Explained
「点个赞」
 Yaohong
Yaohong
点个赞
使用微信扫描二维码完成支付
